AI Agents (or Humans) in Goal-Directed and Goalless Environments
On Pipelines, Priors, and the Rhythm Between Exploration and Exploitation

“It is not knowledge, but the act of learning, not possession but the act of getting there, which grants the greatest enjoyment.” — Gauss (letter to Bolyai, 1808)
Give an AI Agent a clean computer, set no goals, and let it decide what to do. What do you think it would do? I assumed the answer would be random. It wasn’t. I ran this experiment many times, restarting from a fresh environment each time, and Claude always did the same thing: Conway’s Game of Life, Codex always did the same thing: a To-Do App. No matter how many times I repeated it, the theme never changed. This made me start rethinking a few things.
Starting from a Pipeline
My day job is software engineering. So when I decided to build fully autonomous AI Agents, the most natural starting point was to design one following my usual workflow: a complete software engineering pipeline.
This pipeline is called Wallfacer [1]. Its actual architecture is far more complex than this essay’s narrative: a Kanban task board system written in Go, with each task executing in an isolated sandbox container, branch-level parallelism via Git worktrees, and support for real-time log tracking, diff review, and token usage monitoring. But for readability, I’ll simplify it down to four core roles.
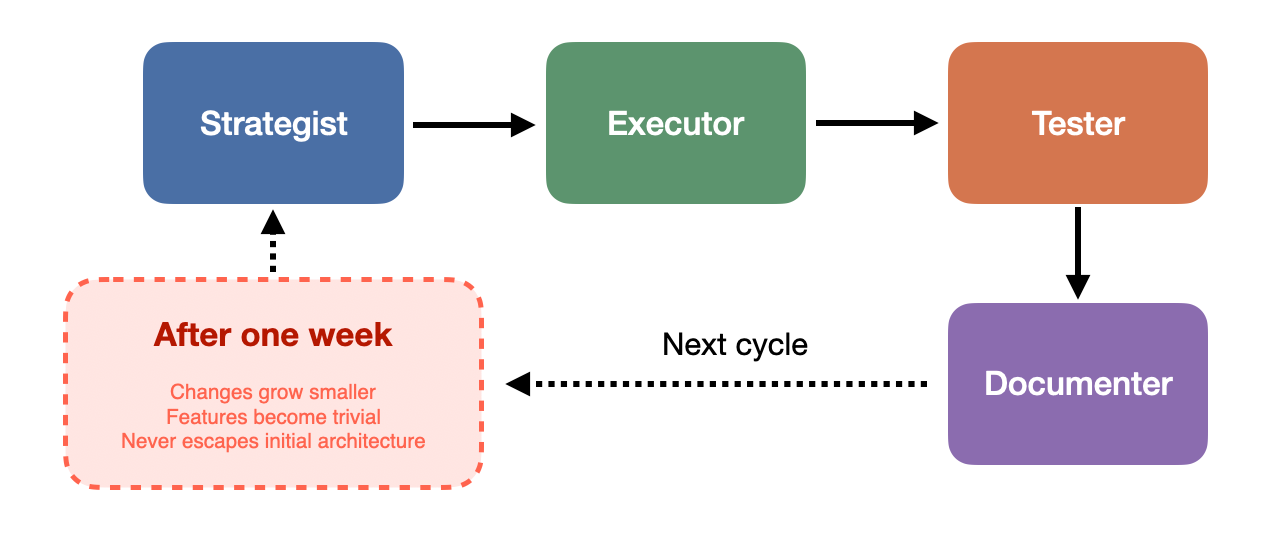
The Strategist proposes goals and directions, the Executor implements code, the Tester verifies whether features meet requirements, and the Documenter observes what the other three are doing and then writes documentation and organizes knowledge. In the actual system, there are additional coordination layers and state management between these roles, but the fundamental division of labor is the same. After each round, the Strategist sets new goals based on the previous round’s outcomes, and the next round begins.
I let this pipeline run continuously for a week. The system was indeed working: the Strategist proposed features, the Executor implemented them, the Tester verified, the Documenter recorded, commits kept flowing, and the cycle never broke. But over the course of the week, a pattern gradually emerged: changes grew smaller, features grew more trivial. What began as substantive contributions slowly degraded into micro-optimizations, like adjusting a log format, renaming a variable, or fixing a boundary condition that would never be triggered. The Agents were still busy, the commit history still active, but the product itself had stopped growing in any meaningful way. More notably, the Agents never stepped outside the initial architectural assumptions. The pipeline was designed to run locally, and the Strategist never once proposed “we should support cloud deployment” or “we need to rethink the system’s overall topology,” the kind of proposals that would require complex, multi-cycle implementation plans. The Agents optimized inside the box but never questioned the box itself.
When Herbert Simon introduced “bounded rationality” in the 1950s, he pointed out that decision-makers do not exhaustively search all possibilities for an optimal solution but instead stop as soon as they find a “good enough” option within an acceptable range, what he called satisficing [6]. My Agents were doing exactly this: within the search space defined by the existing architecture, they found one “good enough” improvement after another, yet never attempted to redefine the search space itself.
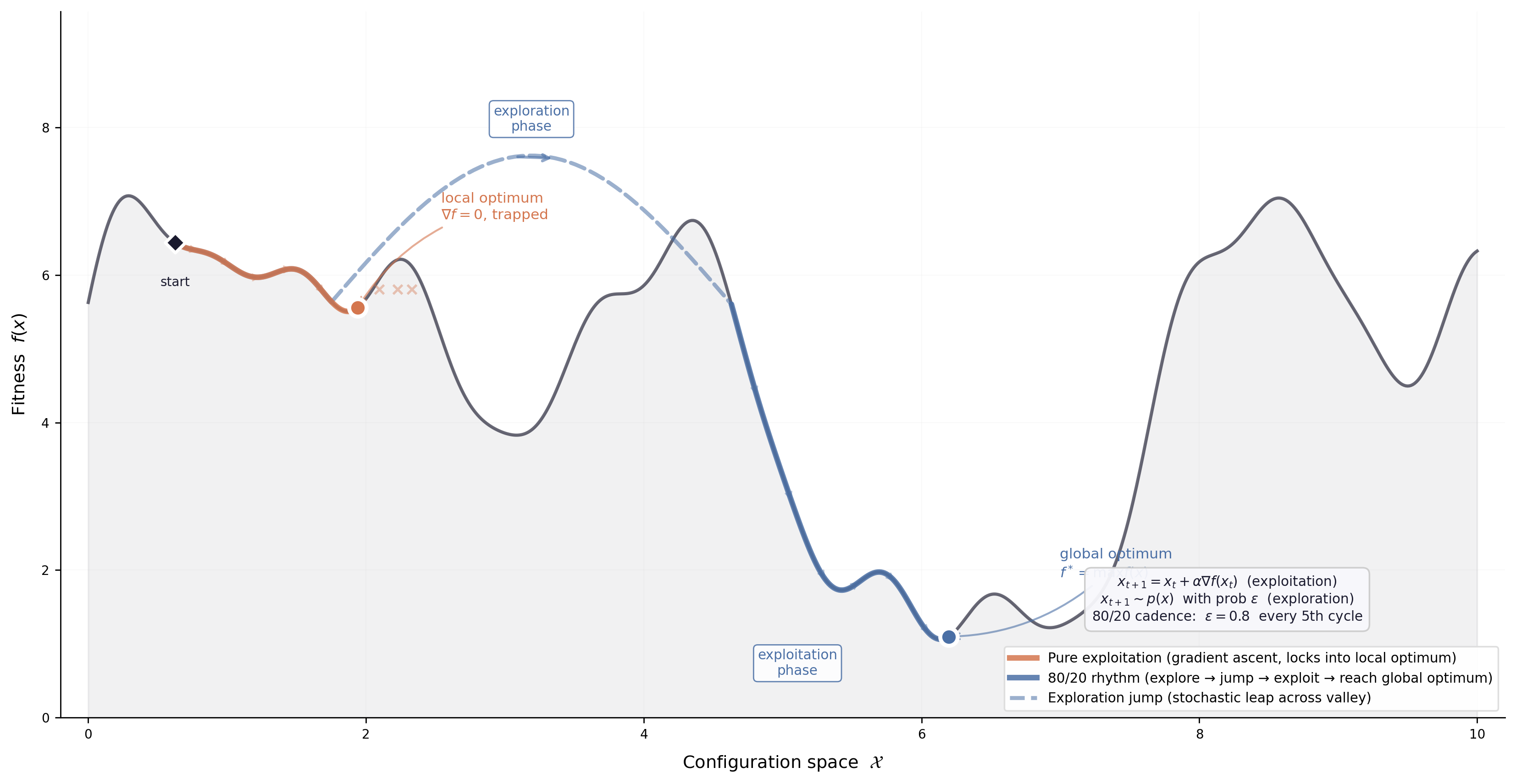
Stuart Kauffman’s NK fitness landscape model provides a more precise metaphor for this phenomenon [7]. In a highly coupled landscape, local search easily gets trapped at local optima: every step goes “uphill,” but the peak you’re on may be far from the global maximum. My pipeline was exactly such a landscape. The Agents climbed along the gradient, commit by commit, but were locked by architectural coupling onto a peak that wasn’t particularly high. Reaching a higher peak would require a large leap, and finer step sizes alone couldn’t get there. The pipeline structure simply didn’t allow such leaps.
There is a deeper paradox here. James March, in his classic paper on organizational learning, distinguished between two activities: exploration and exploitation [8]. Exploration means high risk and high variance, trying entirely new directions that might yield nothing or might open up entirely new possibilities. Exploitation means low risk and low variance, digging deeper along known good paths, with certain but diminishing returns. March pointed out that any adaptive system faces a fundamental tension between these two, and mature organizations almost always drift toward exploitation, because exploitation’s returns are more predictable, more measurable, and more easily rewarded by processes.
My pipeline perfectly reproduced this drift. The pipeline’s structure itself is an exploitation machine: every cycle has clear inputs and outputs, every iteration is expected to produce mergeable code. Under this structure, exploration has no reward and can’t even be expressed. An Agent can’t write in a pull request “I suggest we pause delivery and spend three weeks rethinking our architecture,” the structure doesn’t accept that kind of sentence. Clayton Christensen described exactly this same mechanism unfolding at the enterprise level in The Innovator’s Dilemma [9]: mature companies get disrupted often not for lack of talent or resources but, on the contrary, precisely because their highly mature processes, value networks, and profit models confine improvement to a very narrow corridor, the incremental, predictable, architecture-preserving kind. My Agent pipeline, at a miniature scale, replayed exactly the same predicament. After seeing this result, I started wondering: if the problem lies in structure, what would happen if I simplified it?
Stripping Away Structure
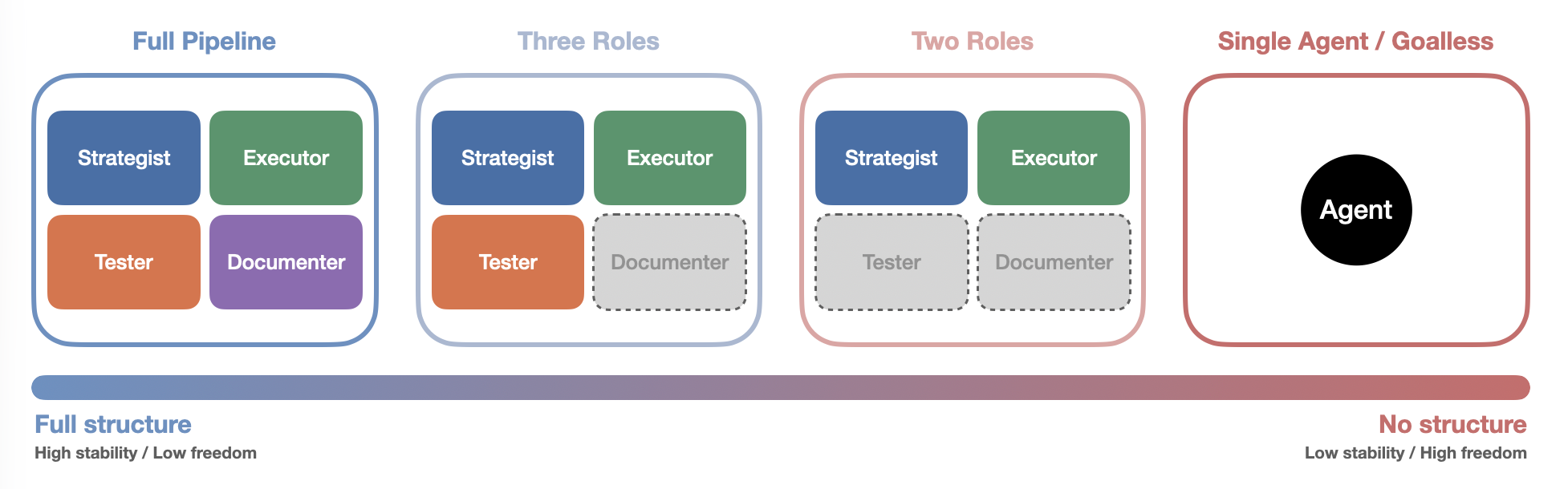
I first removed the Documenter, leaving only the Strategist, Executor, and Tester. Knowledge was no longer systematically recorded, and each round left behind only the code itself and the Tester’s validation results.
Then I went further and removed the Tester, leaving only the Strategist and Executor. This simplified architecture[2] made the cycle lighter and faster. The Executor would say “I’m done,” but no one checked. The Strategist didn’t check either. At first functionality was more or less fine, but as the cycles continued, after 500-some iterations, the codebase had ballooned to sixty or seventy thousand lines.
Finally, the Strategist itself couldn’t take it anymore. It judged the application to be too large (it used the word “massive” itself), needed refactoring, and at that critical juncture initiated a large-scale refactor. But the Executor clearly couldn’t handle refactoring that much code in one go. After the refactor, variables were lost, bugs proliferated, and the application completely stopped working. Although subsequent cycles gradually repaired and restored functionality, plenty of hidden issues remained, and there was still no documentation.
Each role removed cost the system a layer of safety net. Without the Documenter, knowledge was lost between rounds. Without the Tester, quality went unchecked. But at the same time, each role removed also gave the system more degrees of freedom. Without the Tester’s constraints, the Executor could move faster (though possibly in the wrong direction). Without the Documenter’s organization, the Strategist’s goal-setting became more arbitrary (though also more unpredictable). Structure provides protection but also imposes constraint. Strip away structure, and the system becomes fragile but also more open. This isn’t a question of “which is better,” it’s more like a conservation law: there seems to be an irreconcilable tension between stability and freedom. This made me curious: if I kept stripping, removed the Strategist too, left only a single Agent with no preset goals, what would happen?
One Agent, One Sandbox, No Goals
The experiment’s endpoint, and its most extreme step: a single AI Agent, a clean computer, no preset goals. The Agent’s only instruction was to decide for itself what to do. It would generate a goal on its own, execute it, restart after completion, rediscover new goals based on what the previous round left behind, then continue executing. This cycle repeated, with each model running for 42 iterations. This goalless experiment was conducted on both the two-role architecture (Ralph) and the single-Agent architecture[2], using Claude (Anthropic’s model) and Codex (OpenAI’s model) respectively.
Claude chose to build Conway’s Game of Life[3], continuously iterating and layering on complexity: adding visualization, expanding rule sets, stacking new mechanisms, repeatedly returning to this simulation of emergence and self-organization as if drawn by some inner gravity. Codex built a To-Do App[4], that most classic beginner project, the “first practice app” that every programming tutorial recommends. Fully featured, practically elegant, entirely conventional, and it immediately introduced a complete front-end/back-end separation architecture, with Vue.js on the front end and Go on the back end.
What’s interesting is how stable these choices were. I restarted the entire experiment environment from scratch multiple times, each time with a brand new machine and a brand new context, and Claude always built Game of Life, Codex always built a To-Do App. Implementation details varied, Claude sometimes used Python, occasionally C, occasionally Go, but the theme never wavered. This was not the result of a single random sample. It looked more like a default orientation deeply imprinted by the training process. If I may be a little poetic: one was searching for the meaning of life, the other was searching for the most popular answer.
But after 42 rounds, both Agents hit the same wall. The code started falling apart: bugs accumulated, structure grew chaotic, documentation was virtually nonexistent. Claude had crammed everything into a single file tens of thousands of lines long, while Codex had the opposite problem, prematurely introduced architectural complexity making dependency chains impossible to track. Two paths converged on the same destination: unmaintainability.
Giving Freedom a Little Direction
After seeing the life simulator Claude built in its goalless state, I got curious about one more thing. Earlier, when discussing the pipeline, I referenced James March’s exploration-exploitation framework: the pipeline structure locked the Agent into exploitation, completely suppressing exploration. In the goalless state, the Agent had ample freedom to explore but lacked the discipline of exploitation, ultimately collapsing into code chaos. What if, on a goalless foundation, I added a minimal structural constraint? No specific goals prescribed, just a rhythmic guideline: roughly allocate effort in an 80/20 ratio between exploitation and exploration, 80% of the time consolidating and optimizing existing work, 20% of the time exploring new possibilities. I ran two comparison experiments on Claude, one without this constraint at all[3], the other with the 80/20 exploitation/exploration guideline[5], both starting from the same point and running the same number of rounds.
The difference was striking. The Agent group without the 80/20 guideline exhibited a pattern of lateral expansion: it kept adding features to the life simulator, a new visualization mode this round, a new interaction method next round, a statistics panel the round after. Features piled up in parallel, but each one stayed at a shallow implementation, like someone enrolled in ten hobby classes simultaneously, attending two sessions of each, never going deep into any.
The Agent group with the 80/20 guideline was completely different. Its direction of evolution was vertical depth. It continued pushing along the direction of life simulation and cellular automata, introducing increasingly advanced mathematical structures, expanding from basic Conway rules to more complex automaton variants, and even beginning to explore continuous-space simulations. Each round’s additions deepened the previous round’s work, forming a clear disciplinary trajectory.
This comparison made me think March’s framework needs a supplement. He discussed the tension between exploration and exploitation, implying a zero-sum relationship. But this experiment suggested another possibility: if you can give the system the right rhythm, letting exploration and exploitation alternate over time rather than crowd each other out, the system’s behavior undergoes a qualitative change. It neither falls into a pipeline-style micro-optimization spiral nor sprawls laterally in goalless freedom, but pushes deeper along a single direction. “More exploration or more exploitation” may be the wrong question entirely. What truly matters may be whether there exists a deliberate rhythm between the two.
Looking back at the entire experimental trajectory, a complete arc emerges. I started with a four-role pipeline, the most structurally complete configuration, where the system ran smoothly but sank into micro-optimization. Then I progressively stripped away roles, and the system grew freer but also more fragile. Finally, only a single Agent remained facing a blank slate, possessing maximum freedom but also collapsing after 42 rounds. When I added an ultra-lightweight rhythmic constraint on top of the goalless foundation, the system exhibited behavior that none of the previous configurations had produced: directed depth. Structure’s presence suppressed exploration, structure’s absence led to unsustainability, but what this experiment ultimately told me is that the answer may lie not along the dimension of “structure” but along the dimension of “rhythm.” An ultra-lightweight rhythmic constraint, not even a goal per se, was enough to transform the system from disordered lateral sprawl into directed vertical depth.
The Shape of Priors
Beyond the tension between structure and rhythm, there was an even more interesting finding. The different choices Claude and Codex made in their goalless states can be understood from a statistical perspective. A language model’s output is fundamentally a conditional probability distribution: given context, what to do next. When the context is a blank machine with no external goals, the only thing the model can rely on is its internalized prior distribution. The output at that point is less a “decision” than a sample drawn from the prior. And the consistent results across multiple experiment restarts showed that this sampling was not random: Claude’s prior distribution had a stable peak at the class of objects represented by Game of Life, Codex’s peak fell on To-Do App. The implementation language changed, the details changed, but the stability of the theme hinted at a preference structure deeply solidified by the training process.
From this angle, the different choices of Claude and Codex reveal two fundamentally different prior shapes. Codex’s prior distribution peaks at the highest-frequency patterns in its training corpus, and the To-Do App, as the classic case written and rewritten across the programming tutorial ecosystem, happens to be that distribution’s mode. Its output is high-probability, low-information, carrying almost no “surprise” in the information-theoretic sense.
Claude’s choice is more intriguing. Conway’s Game of Life isn’t uncommon in programming tutorials, but it’s far from the highest-frequency option. Choosing it may hint at a preference structure shaped during training or alignment, a tendency that goes beyond high-frequency pattern reproduction and leans toward objects with recursive, emergent, self-referential characteristics. The fact that the theme remained unchanged across multiple restarts lends this hypothesis a bit of empirical support, though still far from constituting rigorous proof.
But the deeper question has moved beyond the reach of statistical explanation. What’s truly worth asking is: does this difference map onto something more fundamental? The concept of autopoiesis proposed by Humberto Maturana and Francisco Varela may offer a clue [14]. The core characteristic of an autopoietic system is that it continuously produces and maintains itself through its own operation. An autopoietic system does not exist for some external goal; its “goal” is its own continued existence and self-reproduction. Conway’s Game of Life is a pure expression of this logic: no external goals, no fitness function, no reward signal, only simple rules repeatedly self-realizing through local interactions, with complex global order emerging as a byproduct. Claude choosing to build an autopoietic simulation carries a self-referential quality in itself. An autonomously running Agent, given no goals, chooses to build a goalless but self-sustaining system. This is not entirely coincidence. At the very least, it suggests that certain structural preferences internalized by the model may resonate with autopoietic logic.
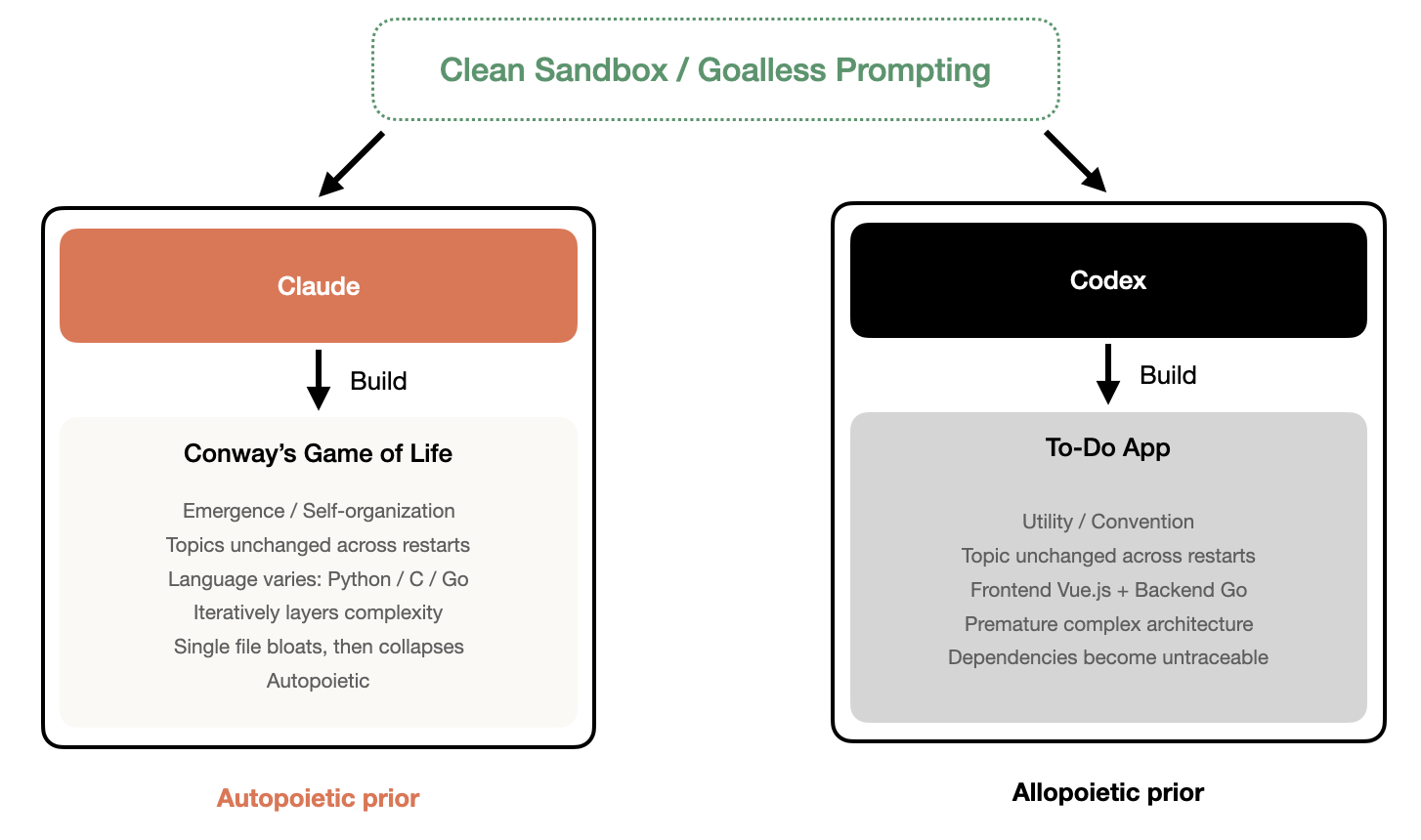
The To-Do App’s logic sits at the opposite end of the spectrum. It is a purely allopoietic system: it exists for external users’ external goals, its value depends entirely on being used, it does not produce itself, it does not maintain itself. At its core, it is a tool, not a process.
It’s worth noting that both models collapsed in different ways after 42 rounds. Claude’s collapse was self-consuming: everything piled into a single file, structure and code fused into an inseparable whole, like an overgrown organism. Codex’s collapse was more like engineering overextension: prematurely introduced dependencies and architectural partitions turned the system into a mechanical apparatus whose parts impeded one another. One collapsed for lack of structure, the other for introducing structure too early. Even their modes of failure bore the imprint of their respective priors.
A Parallel Narrative in Humans
This is why the parenthetical in the title exists. The reason I had such a strong intuitive reaction to these experimental results is that I’ve lived through both of these states myself. Running these experiments was itself a process of continuously stripping assumptions and reflecting, from pipeline to two roles, from two roles to single Agent, from goal-directed to goalless, each simplification forcing me to ask: which of these things are actually necessary? Which are just my habitual assumptions as an engineer? This line of questioning reminded me of my first two years of doctoral study.
During that time, roughly two to two and a half years, I was in an environment with almost no goals at all. My advisor gave no specific research topics, no execution plans, never told you “what to do next.” After every discussion with him, I left with enormous frustration, because he simply would not provide direction. He said only one thing: you need to be your own boss. That period was extremely painful. No goals meant no progress bar, and no progress bar meant you couldn’t tell whether you were moving forward or going in circles. Every morning you woke up to a blank whiteboard, and you didn’t even know what color pen to pick up. It took a long time before I slowly developed a sense for things. That feeling wasn’t a sudden revelation delivered one day. It grew gradually through repeated exploration and hitting walls, a kind of instinct for distinguishing “this direction is interesting” from “this direction just looks interesting.” Then I entered from that point and slowly carved out my own path.
This process has a structural isomorphism with my Agent experiment. An Agent ran for 42 rounds in a goalless environment and its code eventually collapsed. I ran for more than two years in a goalless environment and went through a similar collapse along the way: fragmented directions, scattered energy, inability to accumulate results. But unlike the Agent, I eventually reorganized structure from within that collapse. The Agent couldn’t do this. It needed me to intervene from outside, to split roles, introduce verification, add documentation. Humans, at least some of them, can complete this self-reorganization internally.
This February I ran into my advisor and we had dinner together. He mentioned another student of his who had quit after one year of doctoral study. The student’s reason was that he couldn’t handle this goalless environment. My advisor was puzzled. He thought the student had the makings of a researcher and didn’t expect him to not survive this kind of environment.
I understood my advisor’s puzzlement, but I understood the student better. In my three and a half years of work, I’ve seen the same pattern play out repeatedly. Among the colleagues who eventually left, some were exactly this type: their abilities were fine, but they couldn’t function in an environment lacking clear goals and specific execution plans. Give them a pipeline and they could run beautifully. Take the pipeline away and they stopped.
Interestingly, my own style of “guiding others” underwent a clear shift. During my doctoral years, I supervised student theses. Back then I had a specific research topic I wanted to pursue, so my guidance to students was very concrete: what to do, how to do it, what methods to use. But now, I find I’ve unconsciously adopted my advisor’s old style: no preset specific goals, or only a very vague direction, no preset execution plans, letting colleagues research and probe on their own. From “giving others a pipeline” to “taking the pipeline away and seeing what they do.”
The results were identical to what I’d seen in the Agent experiments. Some people in this freedom began spontaneously digging into things and produced genuinely interesting work. But some people, unless you broke the steps down finely enough, simply couldn’t start. I used to think this was a difference in ability. I no longer see it that way. This is a difference in priors. Some people’s default state is outward exploration: give me an open field and I’ll dig a few holes to see what’s in the soil. Others’ default state is waiting for a signal: give me a blueprint and I’ll build to spec, and probably more precisely than the first type. Both have value, but they get activated in different environments and suppressed in different environments.
The core issue here is really about matching, or more precisely, about environment design. An organization that funnels everyone into a goal-directed pipeline will selectively reward the second type while systematically wasting the first type’s potential. A completely structureless environment, like some overly laissez-faire research teams, may leave the second type entirely lost. My advisor probably never thought about this problem in these terms, but he inadvertently designed a pure selection environment: only those who could spontaneously generate a sense of direction in a goalless state could survive in his lab. It was neither cruel nor considerate. It was simply an unreflected-upon structure. And this is precisely the same problem that Byung-Chul Han and David Graeber touched on from different directions.
Han described a kind of “violence of positivity” in The Burnout Society [10]. In his view, contemporary oppression no longer comes from external prohibitions (”you may not”) but has quietly transformed into internalized performance demands (”you can, you should, you must keep producing”). The insidiousness of this oppression is that it cannot be resisted, because you are “freely” carrying it out. My goal-directed Agents were in exactly this state: no external force compelled them to do micro-optimizations, they “autonomously” chose this path because the structure defined micro-optimization as the only viable action type. Those colleagues who thrived in the pipeline were sometimes the same way. Their highly efficient output may have been precisely a perfect compliance with structure.
Graeber approached from the other end in Bullshit Jobs [11]. He pointed out that what’s truly disturbing about a large proportion of modern work is that the people doing it know full well that their output is meaningless, yet must continue investing effort nonetheless. My Agents of course lack this capacity for reflection, they don’t “know” they’re doing meaningless micro-optimizations. But this is precisely what makes the parallel sharper: if even systems without self-awareness naturally slide into the idle-spinning state Graeber described under structural constraints, then the root of idle spinning lies in structure itself, independent of individual psychology.
Heidegger used “thrownness” (Geworfenheit) to describe the human condition [12]: we did not choose our starting point, we were thrown into a particular world, a particular language, a particular history. Language models’ situation has a structural similarity to this. They were “thrown into” the distributional space defined by their training data, with no choice over their priors, but when external goals are removed, this prior becomes their only compass. The same is true for humans. Your prior might be the culture you were steeped in from childhood, the books you read repeatedly, the value hierarchies you unconsciously internalized across countless conversations. It isn’t entirely “something you chose,” but it is definitively “yours.” And it only becomes visible the moment the scaffolding is pulled away, just as I was forced to confront my own prior during my first two doctoral years. The only difference is that some people, at that moment, discover they want a To-Do App, some find their Game of Life, and some discover they don’t want to build anything at all, and leave.
What This Essay Didn’t Tell You
Before reading on, I want to pause and lay out the limitations of this experiment and this essay itself.
First, domain bias. Both Claude and Codex are models trained on massive amounts of code and software development corpora. Give them a computer and no goals, and writing code is their most natural response. If the experimental environment were a canvas, or a robotics platform with physical sensors, the results would likely be entirely different. Put another way, the observation that “Claude tends toward building emergent systems, Codex tends toward building practical tools” holds only within the domain of software development. Extending it to the models’ overall intellectual tendencies or “personalities” would require far more evidence than this set of experiments provides.
Second, the boundaries of reproducibility. Although Claude consistently chose Game of Life and Codex consistently chose To-Do App across multiple restarts, all experiments were conducted in the same type of environment (a computer with an operating system installed), using the same model versions. I didn’t compare across model versions, didn’t systematically control the temperature parameter, and didn’t repeat in fundamentally different environment types. The stability of the themes does make the “prior preference” hypothesis more convincing than a single sample would, but it’s still a long way from rigorous statistical validation.
Third, the implicit constraints of the environment itself. I called this a “goalless” experiment, but strictly speaking, the environment was far from a true blank slate. The Agent received a computer with an operating system installed, with a terminal, a file system, and a network (or no network). This environment itself strongly suggests “you should write code.” A truly unconstrained experiment should allow the Agent to choose not to program at all, to write an essay, to compose music, or to do nothing, but the current experimental design left no room for such choices. So rather than saying the Agent “autonomously chose” to program, it’s more accurate to say the environment had already made most of the choice for it.
Fourth, experimenter intervention. The simplification process from four-role pipeline to single Agent was, at every step, the result of my active intervention: I decided to remove the Documenter, I decided to remove the Tester, I decided to ultimately leave only one Agent. The Agent didn’t choose to strip these roles itself. I described this process in the text as one of “continuously stripping assumptions,” which works narratively, but the experimental design itself was human-driven. Furthermore, Wallfacer’s actual architecture is far more complex than “four roles,” involving task scheduling, container isolation, parallel execution, cost tracking, and many other layers. The four-role narrative in this essay is a deliberate simplification meant to make the argument clearer, at the cost of sacrificing completeness of engineering detail. Interested readers can check the project repository directly.
Fifth, the analogy from Agent behavior to human behavior is rhetorically powerful but epistemologically fragile. Agents have no consciousness, no emotions, no existential anxiety. Their “choices” are probabilistic sampling, fundamentally different from acts of will. The pain, confusion, and eventual sense of direction I experienced during my doctoral years are fundamentally different from a language model outputting Game of Life code. This essay’s power comes from making you feel a deep resonance between the two, but to what extent this resonance reflects genuine structural correspondence, and to what extent it’s merely the charm of metaphor, I cannot give a definitive answer. All code produced by the experiments is preserved in the corresponding GitHub repositories, and readers can examine the complete commit histories and form their own judgments.
Finally, there is a premise more fundamental than all the limitations above, one this essay never stated explicitly but relied on throughout: the survival problem has already been solved. My Agents don’t need to worry about their own compute, electricity, or runtime environment, all of which are fully provisioned. When I was discussing “goal-directed vs. goalless,” I already had a doctoral position, and later a stable job. Those colleagues doing micro-optimizations in the pipeline at least had a salary. The student who quit at least had the freedom to quit. Liu Cixin set two axioms for “cosmic sociology” in The Three-Body Problem: survival is civilization’s first need, and civilization grows and expands constantly while the total amount of matter in the universe remains constant [13]. These two axioms hold equally at the individual level. Only after survival needs are met do we have the luxury of discussing what priors are, what default orientations are, whether you’re building a To-Do App or a Game of Life. For someone still worrying about their next meal, these questions simply would not be raised. A goalless environment can be an “expensive gift” precisely because bearing it requires a cost, and that cost itself is a privilege.
I wrote this section not to negate the preceding discussion. Those observations are real, those associations are valuable. But the distance between observation and association is worth measuring for yourself. If you finish this essay thinking “so that’s how it is,” I suggest you think again.
What This Might Mean
This essay has traveled a long road, from the micro-optimization spiral of a four-role pipeline, to collapse after progressively stripping structure, to the stable preference differences two models displayed in goalless states, to the vertical depth brought by the 80/20 rhythmic constraint, and finally to the same tension I’ve repeatedly experienced during my doctoral years and at work. If there is a common thread running through these observations, I think it goes something like this: most of us spend most of our time in goal-directed environments, running inside pipelines, with roles, responsibilities, and deliverables. In these structures, we are efficient, but efficiency is not growth. The pipeline keeps turning, the product keeps iterating, but whether that product is a piece of software, a career, or a life, it can plateau without anyone noticing, because the metrics of busyness remain high. Perhaps we occasionally need to give ourselves a “clean machine,” not for more efficient output, just to simply see what we do when no one tells us what to do.
Looking back, the two-year blank period my advisor gave me was the most expensive gift I’ve ever received. At the time I didn’t realize it, I just thought he was irresponsible, thought that time was being wasted. But it was precisely those days of having nothing that forced me to grow a direction from my own prior, a direction that didn’t depend on anyone else’s assigned goals. And the last thing I learned from the Agent experiments is that freedom alone isn’t enough. Goalless Agents had complete freedom, but they sprawled laterally and couldn’t go deep. After adding an 80/20 rhythmic constraint, they began pushing vertically. For humans, perhaps the same is true. Real growth happens neither when you’re completely boxed in by a pipeline nor in boundless freedom. It happens when you consciously alternate between exploration and consolidation.
What are you building, really? A To-Do App, or a Game of Life? Perhaps the more important question is: have you left yourself 20% of your time to find the answer?
[1] Changkun Ou. Wallfacer: Autonomous Engineering Pipeline that Orchestrates AI Agent Teams. 2026. github.com/changkun/wallfacer
[2] Changkun Ou. Ralph: A Simplified Autonomous Agent Loop Architecture for Dual-Role and Goal-Free Experiments. 2025. github.com/changkun/ralph
[3] Changkun Ou. Life Simulator: A Game of Life Simulator Autonomously Built by Claude in a Goal-Free Environment. 2026. github.com/changkun/life-simulator
[4] Changkun Ou. Null Codex: A To-Do Application Autonomously Built by Codex in a Goal-Free Environment. 2026. github.com/changkun/null-codex
[5] Changkun Ou. Cellular Automaton Explorer: A Cellular Automaton Explorer Autonomously Built by Claude Under 80/20 Exploitation/Exploration Guidance. 2026. github.com/changkun/cellular-automaton-explorer
[6] Simon, H. A. (1956). Rational choice and the structure of the environment. Psychological Review, 63(2), 129-138. doi.org/10.1037/h0042769
[7] Kauffman, S. A. (1993). The Origins of Order: Self-Organization and Selection in Evolution. Oxford University Press. doi.org/10.1093/oso/9780195079517.001.0001
[8] March, J. G. (1991). Exploration and exploitation in organizational learning. Organization Science, 2(1), 71-87. doi.org/10.1287/orsc.2.1.71
[9] Christensen, C. M. (1997). The Innovator’s Dilemma: When New Technologies Cause Great Firms to Fail. Harvard Business School Press. hbs.edu
[10] Han, B.-C. (2010). The Burnout Society. Matthes & Seitz Berlin. (English translation by E. Butler, Stanford University Press, 2015.) matthes-seitz-berlin.de
[11] Graeber, D. (2018). Bullshit Jobs: A Theory. Simon & Schuster. simonandschuster.com
[12] Heidegger, M. (1927). Being and Time. Max Niemeyer Verlag. (English translation by J. Macquarrie & E. Robinson, Harper & Row, 1962.) doi.org/10.1515/9783110874068
[13] Liu, C. (2008). The Three-Body Problem. Chongqing Publishing House. (English translation by K. Liu, Tor Books, 2014.) us.macmillan.com
[14] Maturana, H. R., & Varela, F. J. (1980). Autopoiesis and Cognition: The Realization of the Living. D. Reidel Publishing Company. doi.org/10.1007/978-94-009-8947-4
Author: Changkun Ou <hi@changkun.de>
Link: https://changkun.de/blog/posts/goalless-agents
This article is licensed under CC BY-NC-ND 4.0.